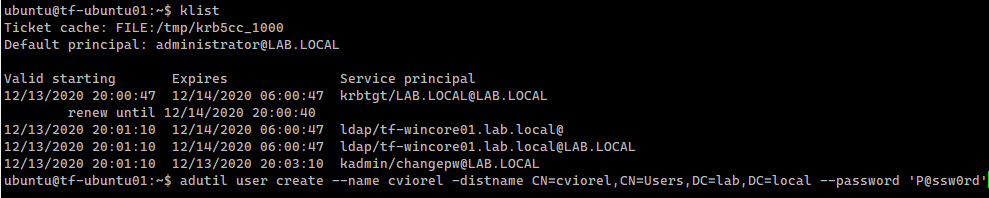
When working with SQL Server, I prefer to have a jump host with my tools already installed.
You may also have them on your main laptop/workstation, but I would also recommend to have a VM in the cloud or in your datacenter.
Everyone has a different list of tools they use, but most of the time you’ll find these apps on those lists:
- command line tools to interact with various cloud providers
- putty
- winscp
- chocolatey
- SQL Server Management Studio
- Azure Data Studio
- git
- vscode
- vim
- various PowerShell modules
In this post I will focus on SQL Server Management Studio.
Since version 18.7, the Azure Data Studio is also included in the installer.
By default Azure Data Studio is installed along with SSMS, but this can be excluded by using:
|
1 |
DoNotInstallAzureDataStudio=1 |
Eventually, this will not be a valid option, as SSMS will require dependencies provided by Azure Data Studio.
This is a good time to update the script I’m using to automatically install the latest version of SSMS.
I could not find an official manifest with the SSMS versions that I could query, so the script is using the GitHub page where Microsoft publishes the SSMS release notes.
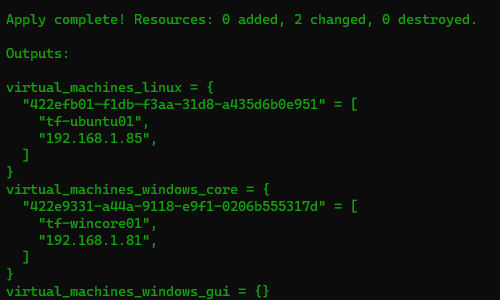
If SSMS is already installed, the script will compare the existing version with the latest one available and it will notify the user.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 |
Function Install-SSMS { <# .SYNOPSIS Silently Download and Install SQL Server Management Studio (SSMS). .DESCRIPTION This will download and install the latest available SSMS from Microsoft. .PARAMETER LocalFile Specifies the path to a local file to install SSMS from. If the local file is not the latest released, the user will be prompted to download the latest one available. If this parameter is not specified, the latest version will be downloaded and installed from https://aka.ms/ssmsfullsetup .PARAMETER InstallAzureDataStudio This will prevent the installation of Azure Data Studio .PARAMETER WriteLog You want to log to a file. It will generate more than a few files :) .PARAMETER RemoveDownload Removes the downloaded file after the installation. .PARAMETER WhatIf Shows what would happen if the command were to run. No actions are actually performed. .PARAMETER Force If this switch is enabled, the installation will continue even if another version of SSMS is found on the system .PARAMETER IgnoreUpdate If this switch is enabled, the installation will always use the LocalFile, even if it's an outdated version. Only works if LocalFile is specified. .PARAMETER EnableException By default, when something goes wrong we try to catch it, interpret it and give you a friendly warning message. This avoids overwhelming you with "sea of red" exceptions, but is inconvenient because it basically disables advanced scripting. Using this switch turns this "nice by default" feature off and enables you to catch exceptions with your own try/catch. .NOTES Author: Viorel Ciucu Website: https://cviorel.com License: MIT https://opensource.org/licenses/MIT .LINK https://www.cviorel.com/silently-download-and-install-sql-server-management-studio-ssms/ https://www.cviorel.com/sql-server-management-studio-automatically-get-the-latest-version/ .EXAMPLE Install-SSMS -WriteLog 1 Silently downloads and installs latest version of SSMS. It will create a log for the installation. .EXAMPLE Install-SSMS -InstallAzureDataStudio $false -WriteLog $true -LocalFile C:\Users\Administrator\Downloads\SSMS-Setup-ENU.exe Silently installs SSMS without Azure Data Studio from the C:\Users\Administrator\Downloads\SSMS-Setup-ENU.exe local file #> [CmdletBinding(SupportsShouldProcess, ConfirmImpact = "Low")] param ( [parameter(Mandatory = $false, ParameterSetName = 'LocalFile')] [string]$LocalFile, [parameter(Mandatory = $false, ParameterSetName = 'LocalFile')] [switch]$IgnoreUpdate, [parameter(Mandatory = $false)] [bool]$InstallAzureDataStudio = $false, [parameter(Mandatory = $false)] [bool]$WriteLog = $false, [parameter(Mandatory = $false)] [bool]$RemoveDownload = $false, [parameter(Mandatory = $false)] [switch]$Force ) if (-not ($PSBoundParameters.ContainsKey('LocalFile'))) { if ($PSBoundParameters.ContainsKey('IgnoreUpdate')) { Write-Output "Parameter IgnoreUpdate can be only used with '-LocalFile'" break } } $temp = ([System.IO.Path]::GetTempPath()).TrimEnd("\") $outFile = "$temp\SSMS-Setup-ENU.exe" $argList = @() $argList += "/install /quiet /norestart" # Check the last version of SSMS $uri = 'https://raw.githubusercontent.com/MicrosoftDocs/sql-docs/live/docs/ssms/release-notes-ssms.md' $md = Invoke-WebRequest -Uri $uri | Select-Object -ExpandProperty Content $regEx = '(- Release number\:\s+(\d+\.)?(\d+\.)?(\d+))|(- Build number\:\s+(\d+\.)(\d+\.)(\d+\.)(\d+))|(- Release date\:\s+(\w+\s+\d{1,2})\,\s+\d{4})' $HashTable = @{} $index = 1 $md | Select-String -Pattern $regEx -AllMatches | ` ForEach-Object { $_.Matches } | ` ForEach-Object { $value = ($_.Value -replace ('-', '')).Trim(); $HashTable.Add($index, $value); $index++ } $lastVersion = @{ ReleaseNumber = (($HashTable[1] -split (':'))[1]).Trim() BuildNumber = (($HashTable[2] -split (':'))[1]).Trim() ReleaseDate = (($HashTable[3] -split (':'))[1]).Trim() } $filter = 'Microsoft SQL Server Management Studio' $uninstall32 = Get-ChildItem "HKLM:\SOFTWARE\Wow6432Node\Microsoft\Windows\CurrentVersion\Uninstall" | ForEach-Object { Get-ItemProperty $_.PSPath } | Where-Object { $_ -match $filter } | Select-Object DisplayVersion $uninstall64 = Get-ChildItem "HKLM:\SOFTWARE\Microsoft\Windows\CurrentVersion\Uninstall" | ForEach-Object { Get-ItemProperty $_.PSPath } | Where-Object { $_ -match $filter } | Select-Object DisplayVersion if ($uninstall64) { $isInstalled = $true $installedVersion = $uninstall64.DisplayVersion } if ($uninstall32) { $isInstalled = $true $installedVersion = $uninstall32.DisplayVersion } if ($isInstalled -eq $true) { Write-Output "Version $installedVersion was detected on your system!" if (-not $Force) { $confirmation = Read-Host "Are you sure you want to proceed [y/n]" if ($confirmation -notmatch "[yY]") { break } } } if ($LocalFile.Length -ne 0) { if (Test-Path -Path $LocalFile) { $existingVersion = (Get-ChildItem -Path $LocalFile).VersionInfo.ProductVersion if ($existingVersion -ne $lastVersion.BuildNumber) { Write-Output "There is a newer release available: $($lastVersion.ReleaseNumber) ($($lastVersion.ReleaseDate)). We will download it and save it to: $($outFile)" if (-not $IgnoreUpdate) { $outdated = $true } } } else { Write-Output "The file path is not valid." $LocalFile = $null } } if ($null -eq $LocalFile -or $LocalFile.Length -eq 0) { if (Test-Path -Path $outFile) { $existingVersion = (Get-ChildItem -Path $outFile).VersionInfo.ProductVersion if ($existingVersion -ne $lastVersion.BuildNumber) { Write-Output "Locally-cached copy exists, but it's outdated. There is a newer version available $($lastVersion.ReleaseNumber) (released on $($lastVersion.ReleaseDate)). We will download it and save it to: $($outFile)" $outdated = $true } } if ((Test-Path -Path $outFile) -and (-not $outdated)) { Write-Output "Locally-cached copy exists and it's the newest one available, skipping download." } else { if ($PSCmdlet.ShouldProcess($env:COMPUTERNAME, "Downloading latest SSMS to $outFile")) { try { # Create SSL/TLS secure channel [Net.ServicePointManager]::SecurityProtocol = [Net.SecurityProtocolType]::Tls12 # Start the download $url = "https://aka.ms/ssmsfullsetup" try { $ProgressPreference = "SilentlyContinue" Invoke-WebRequest $url -OutFile $outFile -UseBasicParsing } catch { (New-Object System.Net.WebClient).Proxy.Credentials = [System.Net.CredentialCache]::DefaultNetworkCredentials Invoke-WebRequest $url -OutFile $outFile -UseBasicParsing } } catch { Write-Output "Download failed. Please download manually from $url." return } } } } if ($InstallAzureDataStudio -eq $false) { $argList += "DoNotInstallAzureDataStudio=1" } if ($WriteLog -eq $true) { $logFile = "$temp\SSMS_$(Get-Date -Format `"yyyyMMddHHmm`").txt" $argList += "/log $logFile" Write-Output "InstallationLog: $logFile" } # Start the install if ($PSCmdlet.ShouldProcess($env:COMPUTERNAME, "Installing latest SSMS from $outFile")) { # Closing running SSMS processes if (Get-Process 'Ssms' -ErrorAction SilentlyContinue) { Stop-Process -Name Ssms -Force -ErrorAction SilentlyContinue } # Install silently if (Test-Path $outFile) { if ($outFile.EndsWith("exe")) { Write-Output "Performing silent install..." $process = Start-Process -FilePath $outFile -ArgumentList $argList -Wait -Verb RunAs -PassThru if ($process.ExitCode -ne 0) { Write-Output "$_ exited with status code $($process.ExitCode). Check the error code here: https://docs.microsoft.com/en-us/windows/win32/msi/error-codes" } else { Write-Output "Instalation was sucessfull!" } } } else { Write-Output "$outFile does not exist. Probably the download failed." } } # Cleanup if ($RemoveDownload -eq $true) { if ($PSCmdlet.ShouldProcess($env:COMPUTERNAME, "Removing the installation file $outFile")) { Remove-Item $outFile -Force -ErrorAction SilentlyContinue } } } |
You can also reference this script directly from my GitHub account.
Feel free to grab it and share it you you find it useful.