The complete code can be found on my GitHub account
As a SQL Server person, I usually need to work with full blown Availability Groups for my various test scenarios.
I need to have a reliable and consistent way to rebuild the whole setup, multiple times a day.
For this purpose, docker containers are a perfect fit.
This approach will serve multiple scenarios (tsql development, performance tuning, infrastructure changes, etc.)
Target
Using the process I’ll explain below, I will deploy:
- 3 nodes running SQL Server 2019 Dev on top of Ubuntu 18.04
- 1 Clusterless Availability Group (also known as Read-Scale Availability Group)
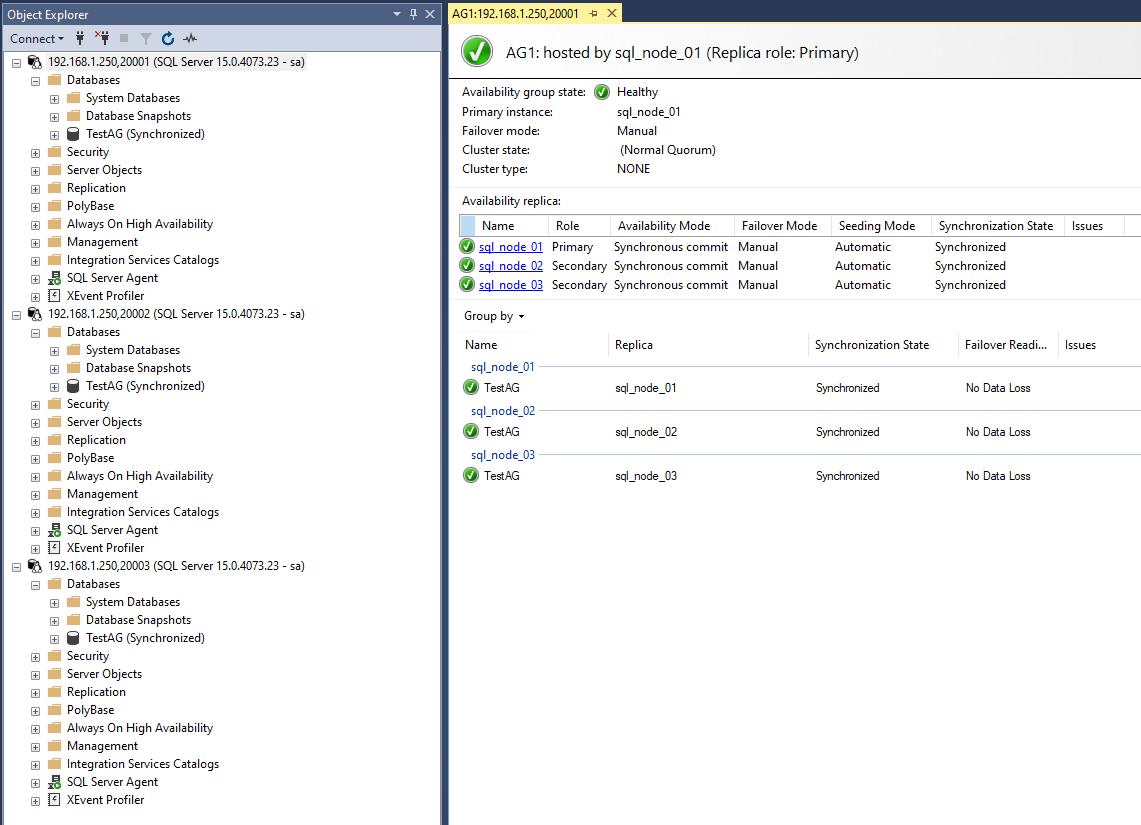
Note that our Clusterless AG is not a high availability or disaster recovery solution.
It only provides a mechanism to synchronize databases across multiple servers (containers).
Only manual failover without data loss and forced failover with data loss is possible when using Read-Scale availability groups.
For production ready and true HA and DR one should look into traditional availability groups running on top of Windows Failover Cluster.
Another viable solution is to run SQL Server instance on Kubernetes in Azure Kubernetes Service (AKS), with persistent storage for high availability.
How
The workflow consist of the following steps:
- prepare a custom docker image running Ubuntu 18.04 and SQL Server 2019

- create a configuration file that will be used by docker-compose to spin up the 3 nodes
The actual build of the Availability Group will be performed by the entrypoint.sh script that will run on all the containers based on the image we just created.
The entrypoint.sh file is used to configure the container.
We just need to add a few .sql scripts that will get executed using sqlcmd utility.
In this case is the ag.sql file that contains the commands to create logins, certificates, endpoints and finally the Availability Group.
Remember, we’re using a Clusterless Availability Group, so the SQL Server service on Linux uses certificates to authenticate communication between the mirroring endpoints.
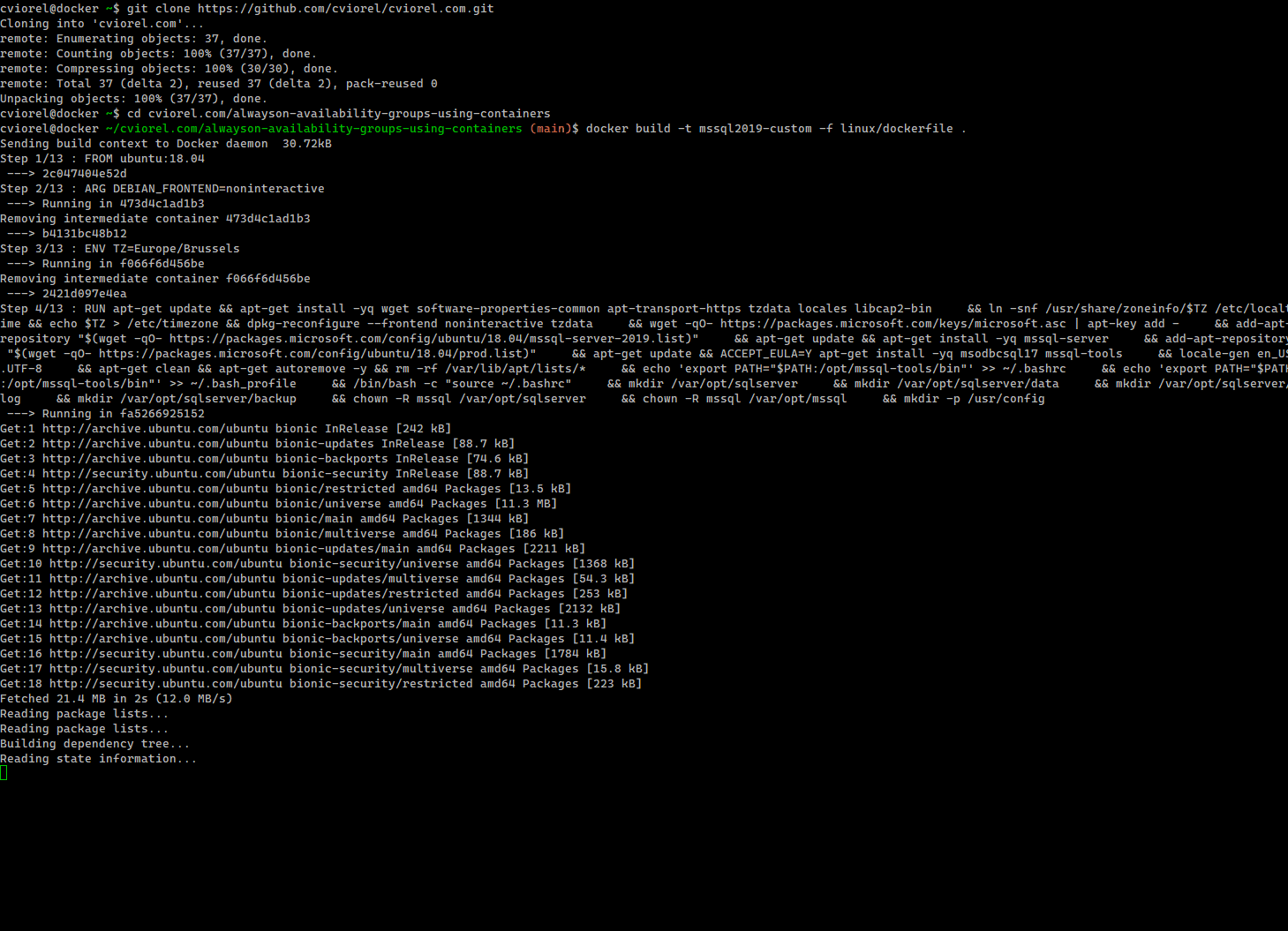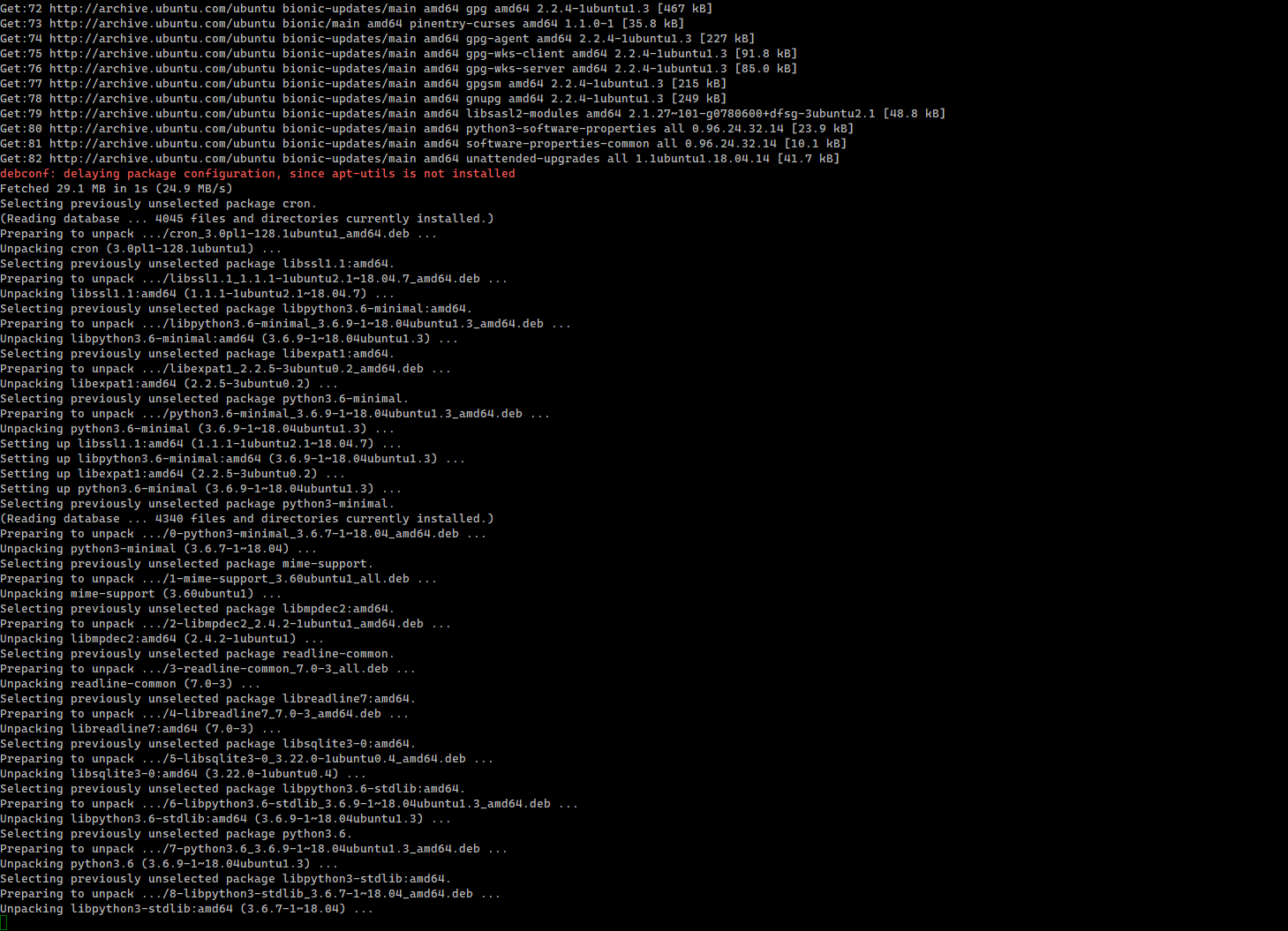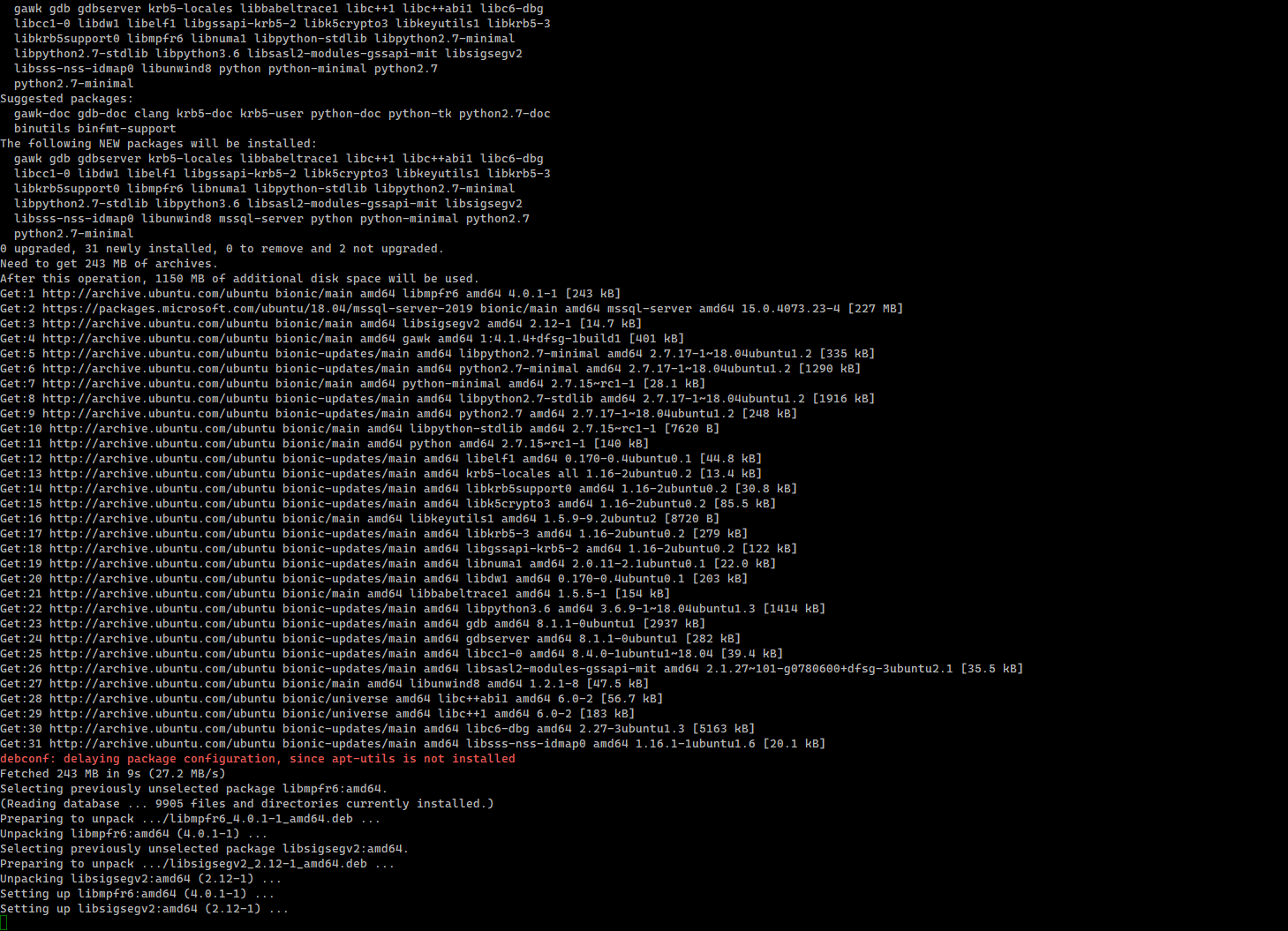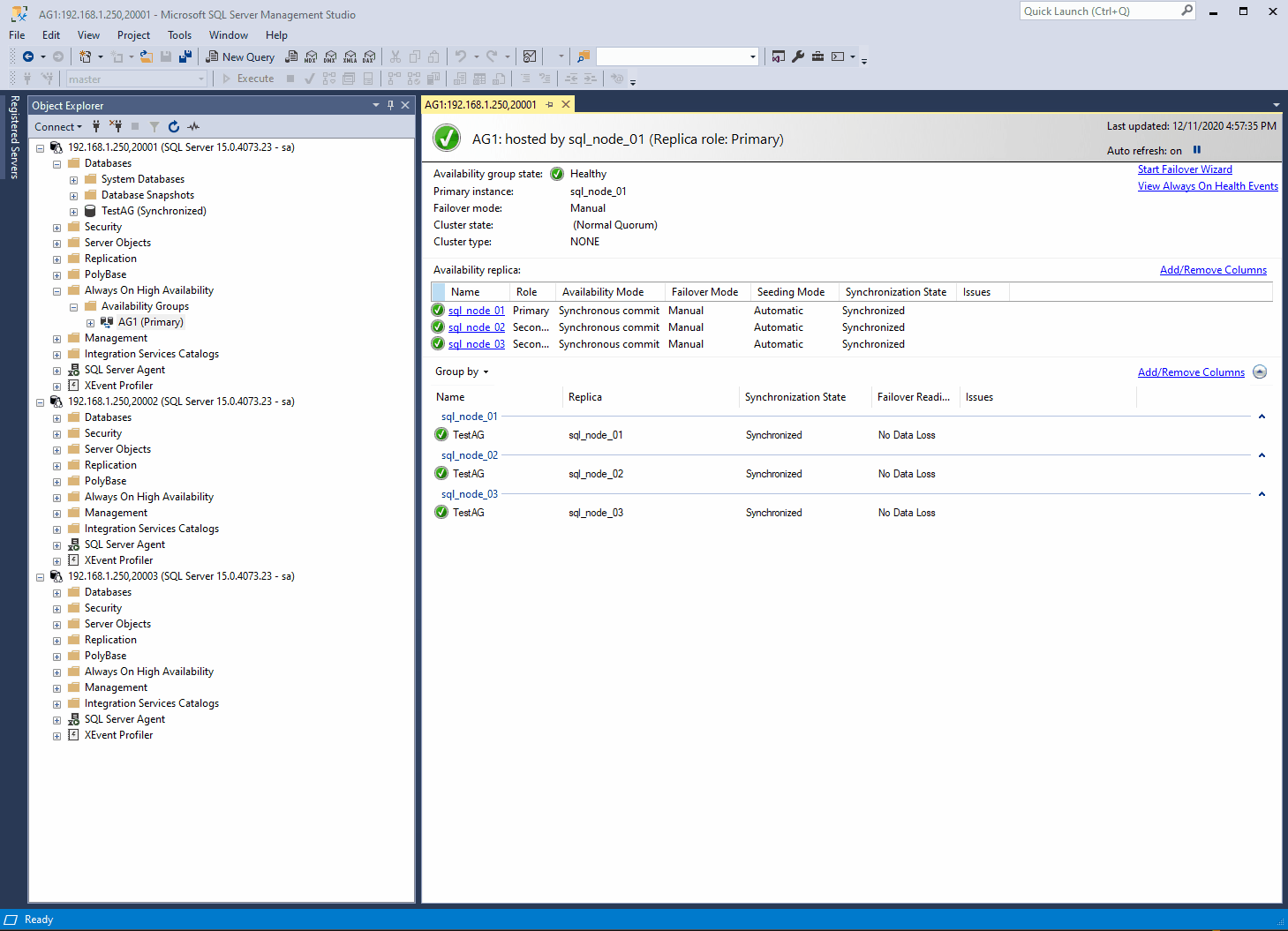
In a matter of minutes I have a fully working AG.
Credentials
During the build of the docker image and to create the AG I will need to specify various variables and credentials.
For production environments the recommended approach to manage secrets is to use a vault.
For my case I’m storing various variables and credentials in plain text files in the env folder.
Docker will parse those files and they will be available as environment variables.
- sapassword.env – this contains the SA password and it’s needed when the custom image is built.
|
1 |
SA_PASSWORD=Str0ngPa$$w0rdForSA! |
- sqlserver.env – various variables are set here and are needed when the custom image is built.
|
1 2 3 4 5 6 |
ACCEPT_EULA=Y MSSQL_DATA_DIR=/var/opt/sqlserver/data MSSQL_LOG_DIR=/var/opt/sqlserver/log MSSQL_BACKUP_DIR=/var/opt/sqlserver/backup MSSQL_PID=Developer MSSQL_AGENT_ENABLED=1 |
- miscpassword.env – will be needed to create the login and certificate needed by the Availability Group. This file is actually added to the container and it will be deleted after the Availability Group is created.
|
1 2 3 |
:SETVAR sa_password "Str0ngPa$$w0rdForSA!" :SETVAR encryption_password "Str0ngPa$$w0rdForEnc!" :SETVAR dbm_login_password "Str0ngPa$$w0rdForDBM!" |
The advantage of this approach is that I have only one place where I store all these variables and credentials, but as I mentioned earlier, it’s not a proper solution from a security standpoint.
A few alternative approaches would be:
– use a tool to manage secrets, like Vault
– multi-stage builds
– use BuildKit
Conclusion
From a testing and development point of view, this solution works very well for me as I can rebuild the environment in a fast and consistent way.
It’s not by any means the best option out there, but it’s really simple to use and reproduce.
See it in action
Click on the image for the full gif